5 Ways Pretrained Models Improve Semantic Consistency
Pretrained models make AI responses more consistent by ensuring they align in meaning, even when questions are phrased differently. This is crucial for reliability, especially in specialized fields where terms can have multiple meanings. Here's how these models achieve semantic consistency:
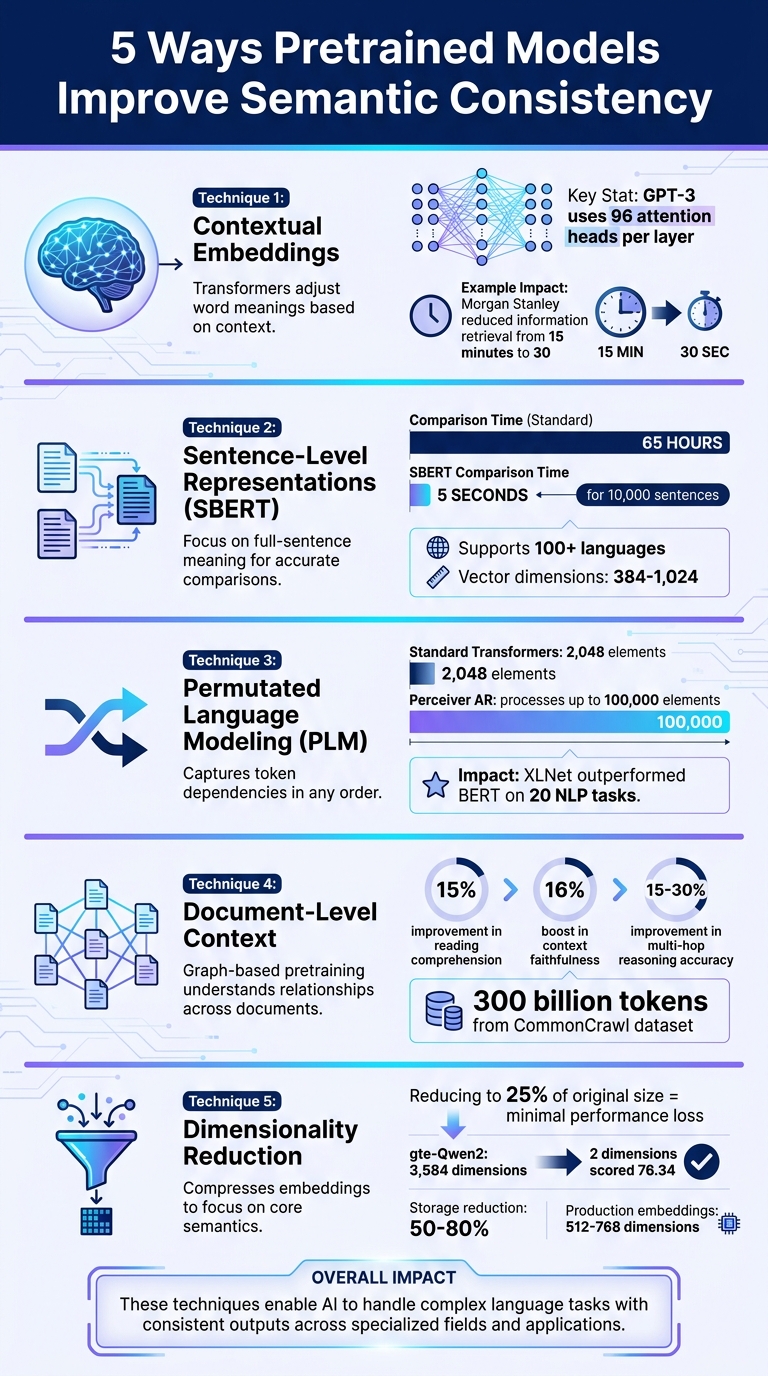
- Contextual Embeddings: Transformers adjust word meanings based on context, reducing ambiguity.
- Sentence-Level Representations (SBERT): Focus on full-sentence meaning, enabling faster and more accurate comparisons.
- Permutated Language Modeling (PLM): Captures token dependencies in any order, solving issues like reversed relationships.
- Document-Level Context: Uses graph-based pretraining to understand relationships across multiple documents.
- Dimensionality Reduction: Compresses embeddings to focus on core semantics while maintaining performance.
These techniques allow models to handle complex language tasks, deliver consistent outputs, and improve efficiency across various applications. For example, SBERT reduces sentence comparison time from 65 hours to 5 seconds, and PLM enhances long-form content generation. Pretrained models are reshaping how AI processes and understands language.
5 Techniques Pretrained Models Use to Improve Semantic Consistency in AI
1. Contextual Embeddings Through Transformer Architecture
Transformers have revolutionized how word meanings are understood by making them context-sensitive. Unlike earlier models that assigned a single, fixed meaning to each word - like "bank" always referring to the same concept, whether it was about money or a river - transformers adapt word meanings based on the surrounding context. This shift reduces ambiguity and forms the basis of the self-attention mechanism.
Self-attention allows the model to evaluate the importance of every word in a sentence, no matter how far apart they are. For example, in the sentence, "The animal didn't cross the street because it was too tired", the mechanism correctly links "it" to "animal" rather than "street". This capability addresses a major limitation of older sequential models, which often struggled with interpreting relationships between distant words.
"The multi-head self-attention mechanism allows the model to attend to different positions of the input sequence across multiple subspaces, thereby capturing diverse semantic relationships." - Yanfang Ye et al., University of Notre Dame
The multi-head attention mechanism, as seen in GPT-3 with its 96 attention heads per layer, adds another layer of sophistication. Each attention head can focus on distinct aspects of language simultaneously - one might track grammatical structures, while another resolves pronoun references. This parallel processing ensures the model maintains meaning across words, sentences, and even entire documents, handling complex language with ease.
A practical example of this technology in action came in May 2023, when Morgan Stanley introduced a GPT-4 powered assistant for 15,000 financial advisors. The system processed over 100,000 research documents, reducing the time needed to locate and synthesize financial information from 15 minutes to just 30 seconds. This kind of precision in specialized fields demonstrates how transformative these advancements can be, paving the way for further developments explored in the next sections.
sbb-itb-903b5f2
2. Sentence-Level Semantic Representations with SBERT
Transformers are great at understanding the context of individual words, but SBERT (Sentence-BERT) takes things a step further by grasping the meaning of entire sentences. SBERT transforms full sentences into fixed-size vectors (ranging from 384 to 1,024 dimensions) using a Siamese network architecture. This allows for comparisons based on the overall meaning of sentences, rather than just analyzing individual words. In essence, SBERT builds on transformer embeddings by focusing on full-sentence semantics.
The efficiency improvement is striking. For example, comparing 10,000 sentences using a standard BERT cross-encoder can take around 65 hours. With SBERT, the same task takes about 5 seconds by leveraging cosine similarity. This speed is possible because SBERT encodes sentences independently, making comparisons far simpler - no need to process every possible sentence pair together.
"Sentence-BERT (SBERT), a modification of the pretrained BERT network that use siamese and triplet network structures to derive semantically meaningful sentence embeddings that can be compared using cosine-similarity." - Nils Reimers and Iryna Gurevych, Authors of Sentence-BERT
SBERT also tackles semantic ambiguity through contrastive training. This technique pulls semantically similar sentences closer in the vector space while pushing dissimilar ones apart. It becomes especially adept at handling subtle differences by using hard-negative mining - training on sentences that appear similar superficially but differ in meaning.
The applications for SBERT are wide-ranging. For instance, it powers semantic search systems that can recognize "cheap accommodation" and "affordable hotels" as referring to the same idea, even though the phrases don’t share any common words. Additionally, SBERT supports over 100 languages, aligning semantically similar content across languages within the same vector space. This ability to unify multilingual and nuanced sentence representations strengthens its role in cross-domain text generation and semantic analysis.
3. Enhanced Token Dependencies via Permutated Language Modeling
Pretrained models have taken a leap forward in addressing token dependency challenges, thanks to advanced training methods that go beyond traditional contextual and sentence-level embeddings.
One major issue with older language models is the "reversal curse." For instance, if a model learns "A's father is B", it often fails to answer "Who is B's child?" despite having seen the information during training. This limitation arises because traditional models predict words sequentially - always looking forward, never backward. Unlike these older approaches, Permutated Language Modeling (PLM) introduces a way to capture token dependencies across various contexts.
How Permutated Language Modeling (PLM) Works
PLM trains models on all possible orderings of a sequence, not just in a left-to-right fashion. This approach ensures models learn relationships between tokens, regardless of their position in the sequence. Semantic-aware Permutation Training (SPT), a refinement developed by Microsoft Research, takes this a step further. It preserves meaningful phrases like "New York" during permutations, ensuring that key concepts stay intact.
"The root cause of the reversal curse lies in the different word order between the training and inference stage, namely, the poor ability of causal language models to predict antecedent words within the training data." - Qingyan Guo, Researcher, Microsoft Research
Real-World Impact of PLM
Experiments with LLaMA-7B show that models trained using SPT achieve near-equal performance on forward and reverse tasks. This is achieved by training the model using three types of permutations: original, reversed, and randomly shuffled sequences. By doing so, the model learns to understand both preceding and following contexts.
XLNet, one of the first models to implement PLM, demonstrated its effectiveness by outperforming BERT on 20 different NLP tasks. Unlike BERT, which treats masked tokens independently, XLNet captures dependencies between all tokens, enabling a more comprehensive understanding of text. This bidirectional learning approach is particularly well-suited for tasks requiring long-form and cross-domain text generation, where understanding distant relationships between tokens is critical.
Applications in Long-Form and Cross-Domain Content
PLM shines in scenarios requiring semantic coherence across lengthy documents. For example, models like Perceiver AR can now process sequences of up to 100,000 elements - far exceeding the 2,048-token limit of standard Transformers. A 60-layer Perceiver AR model with an 8,192-token context even outperformed a 42-layer Transformer-XL in generating book-length content, all while running faster. This ability to maintain consistency across long sequences makes PLM a game-changer for generating cohesive, large-scale content and handling complex, cross-domain tasks effectively.
4. Document-Level Context Through Graph-Based Pretraining
Graph-based pretraining takes contextual reasoning to the next level by organizing documents based on semantic relevance, rather than processing them in a random order. Unlike traditional methods that focus on tokens or sentences, this approach uses a document graph, where each document becomes a node and edges represent semantic similarity. This setup allows models to understand relationships across multiple documents, rather than limiting reasoning to isolated ones.
In March 2024, researchers from Meta AI and the University of Washington, including Weijia Shi and Luke Zettlemoyer, introduced "In-Context Pretraining" (ICLM). Using 300 billion tokens from the CommonCrawl dataset, they reordered documents to prioritize semantic similarity. The reordering process relied on an algorithm similar to the Maximum Traveling Salesman Problem. The results were impressive: reading comprehension improved by 15%, and context faithfulness saw a 16% boost. These findings highlight the potential of this method to enhance model performance significantly.
"In-Context Pretraining... explicitly encouraging them to read and reason across document boundaries." - Weijia Shi, Lead Author, Meta AI
This graph-based structure provides a framework for understanding relationships between entities, going beyond simple statistical patterns. The benefits are clear: models trained with this method demonstrated a 15–30% improvement in multi-hop reasoning accuracy. For instance, they could link a business to its industry, location, and products more effectively. Additional advantages included an 8% increase in in-context learning and a 9% boost in retrieval-augmented generation performance.
For businesses, the impact is equally significant. Companies utilizing structured knowledge graphs have tripled their discovery rates through AI queries. Moreover, entities with five or more property types showed a 40% stronger semantic association in LLM vector spaces. By reinforcing semantic consistency across documents, graph-based pretraining complements earlier techniques that focus on token and sentence-level coherence.
5. Dimensionality Reduction and Semantic Clustering
Dimensionality reduction and semantic clustering take pretrained models a step further by refining how they maintain consistency across various domains. High-dimensional embeddings often contain redundant information, which can obscure the core semantic patterns. Dimensionality reduction solves this by compressing embeddings to their essential components - removing noise while keeping the critical semantics intact. Research from Nagoya University highlights this well: reducing embeddings to just 25% of their original size led to minimal performance loss. For instance, the gte-Qwen2 model (initially 3,584 dimensions) scored 76.34 on classification tasks using only 2 dimensions. This even outperformed the E5-large embeddings at 1,024 dimensions, which scored 75.69. In clustering tasks, reducing gte-Qwen2 embeddings to just 128 dimensions (3.6% of the original size) resulted in a performance drop of only 0.8 points. This shows how compression forces models to focus on general semantic patterns rather than overly specific details.
"High-dimensional data can suffer from the curse of dimensionality, making it difficult to find meaningful clusters." - Gurpreet Johl, Author of Hands-On LLMs
When paired with dimensionality reduction, semantic clustering organizes data into meaningful groups. For example, a study of 44,949 NLP abstracts from Arxiv used a clustering pipeline to identify 159 distinct clusters. This process often relies on density-based algorithms like HDBSCAN, which are particularly effective because they filter out outliers instead of forcing every data point into a cluster. In one analysis, 13,040 documents that lacked clear thematic similarity were correctly classified as outliers, ensuring the remaining clusters were more coherent.
In production environments, embeddings are typically reduced to dimensions ranging from 512 to 768 for storage efficiency, while setups balancing quality and storage use 1,024 to 1,536 dimensions. For handling complex nonlinear relationships in high-dimensional data, UMAP (Uniform Manifold Approximation and Projection) often outperforms PCA, making it the go-to tool for semantic clustering. By leveraging these approaches, storage needs can be cut by 50–80% without sacrificing semantic consistency across domains. These techniques add a final layer of refinement to pretrained models, ensuring they maintain semantic clarity while optimizing for efficiency.
Conclusion
Pretrained models have transformed the way we create text that is both coherent and contextually accurate across various fields. These models rely on several key components: transformer architectures that use attention mechanisms to focus on relevant parts of the input, sentence-level representations that preserve meaning beyond individual words, and self-supervised learning objectives that teach models the relationships between tokens and the structure of language. Together, these elements allow models to absorb and process vast amounts of information during pretraining.
By distilling knowledge from extensive datasets - ranging from web pages to books and even code repositories - pretrained models uncover the patterns and structures underlying language. Take Google's T5, for example. Trained on an impressive 7 TB of data, T5 can handle tasks like summarization and question answering straight out of the box.
"The beauty of T5 is precisely that it is 'one model to rule them all,' i.e., you can use one pre-trained model for almost any NLP task." - Nauman Mustafa, Senior Deep Learning Engineer at VisionX
Building strong base models, such as LLaMA-2 7B, highlights the importance of high-quality, curated data. Training LLaMA-2 required 184,000 A100 GPU-hours and an estimated $6 million. This underscores a growing preference for prioritizing data quality over sheer volume. For instance, a well-curated 300 billion-token dataset can produce a more effective model than a larger, less refined 3 trillion-token dataset. Additionally, techniques like Low-Rank Adaptation (LoRA) drastically reduce the number of trainable parameters - by up to 10,000× - while maintaining model performance. This makes it easier and more cost-effective for organizations to fine-tune these models for specific applications.
Advancements like these are making AI more accessible. Tools such as NanoGPT offer a pay-as-you-go model, enabling broader access to powerful AI capabilities. These pretrained models, with their advanced semantic understanding, are now within reach for tasks ranging from developing contextual chatbots to analyzing legal documents - without the steep costs associated with custom training.
FAQs
How do contextual embeddings reduce word ambiguity?
Contextual embeddings help reduce word ambiguity by examining the context in which a word appears. By analyzing the surrounding text, models can distinguish between different meanings of the same word, leading to a more precise understanding and application of language.
When should I use SBERT instead of a cross-encoder?
SBERT is perfect when you need sentence embeddings for tasks such as similarity search, clustering, or retrieval. It generates embeddings that you can compare using cosine similarity. This makes it ideal for scenarios where reusable embeddings are a priority.
On the flip side, cross-encoders are better suited for tasks where you need to directly score specific sentence pairs. However, they don’t produce reusable embeddings, so they’re more task-specific.
How do PLMs help models stay consistent in long documents?
Pretrained Language Models (PLMs) play a key role in maintaining consistency throughout lengthy documents by ensuring semantic coherence across extended contexts. To achieve this, techniques like coherence boosting are used to improve the model's ability to focus on long-range dependencies within the text. Additionally, gradient modulation helps by dynamically adjusting updates, which minimizes the risk of contextual drift over time.
These methods allow PLMs to better track relationships and connections within complex, lengthy texts, ensuring that the generated content stays aligned with the overall narrative or discourse.