Performance Benchmarks for OOD Generalization
Out-of-distribution (OOD) generalization is about how well AI models handle unfamiliar data - scenarios they weren’t explicitly trained for. This matters in fields like autonomous driving or medical diagnostics, where unexpected situations can arise. The article explores key benchmarks and challenges in evaluating and improving OOD performance. Here’s a quick summary:
-
Key Benchmarks:
- WOODS: Tests time series data like wearables and videos, revealing struggles with temporal shifts.
- OODBench: Focuses on vision-language models, highlighting their weaknesses with unfamiliar object instances.
- HAROOD: Evaluates human activity recognition using sensor data across different scenarios.
- LAION-C: Introduces new distortions to test models trained on massive datasets.
-
Challenges:
- Models often rely on unstable shortcuts, leading to poor performance in unfamiliar scenarios.
- Benchmarks sometimes fail to disrupt spurious correlations, giving a false sense of robustness.
- Time series and sensor data remain under-researched compared to image-based benchmarks.
-
Improvements:
- Techniques like Invariant Risk Minimization (IRM) and domain generalization help but aren’t universally effective.
- Benchmark-driven training with diverse datasets is critical for better OOD handling.
- Testing across multiple distribution shifts ensures models are reliable in practical settings.
The article emphasizes that while progress has been made, creating better benchmarks and refining algorithms is essential to address OOD challenges effectively.
Benchmarking Out-of-Distribution Generalization Capabilities of DNN-based Encoding Models for the...
sbb-itb-903b5f2
Major OOD Benchmarks
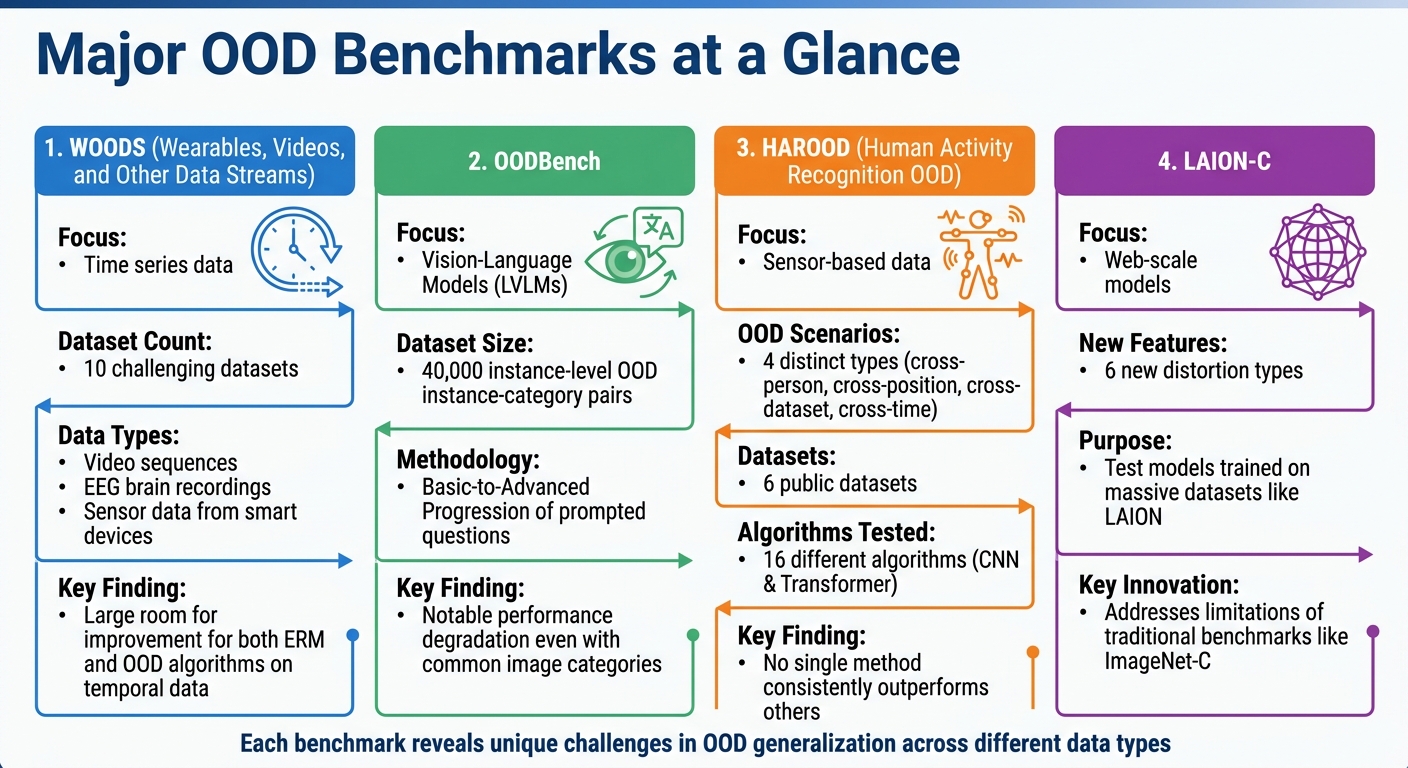
Major OOD Benchmarks Comparison: WOODS, OODBench, HAROOD, and LAION-C
Specialized benchmarks have been created to test how AI models perform when faced with distribution shifts across different types of data. These benchmarks help identify where models struggle in unfamiliar situations, offering valuable insights for improving their reliability.
WOODS: Time Series OOD Benchmarks

WOODS (Wearables, Videos, and Other Data Streams) centers on time series data, which has received less focus compared to static computer vision tasks. This suite includes 10 challenging datasets covering areas like video sequences, EEG brain recordings, and sensor data from smart devices.
What sets WOODS apart is its structured approach to evaluating temporal distribution shifts. The WOODS Project Team highlights a major issue:
Our experiments show a large room for improvement for empirical risk minimization and OOD generalization algorithms on our datasets, thus underscoring the new challenges posed by time series tasks.
Tests reveal that both standard empirical risk minimization (ERM) methods and specialized OOD algorithms struggle to generalize well on temporal data. This underscores the unique difficulties posed by time series, which differ significantly from static image challenges.
OODBench: Vision-Language Model Evaluations
Moving from time series to vision-language tasks, OODBench offers another perspective. This benchmark evaluates Large Vision-Language Models (LVLMs) using 40,000 instance-level OOD instance-category pairs. Unlike traditional benchmarks, it uses a "Basic-to-Advanced Progression" of prompted questions to test how models handle unfamiliar objects within otherwise familiar image categories.
The findings are striking. As Ling Lin and colleagues observed:
Current VLMs still exhibit notable performance degradation on OODBench, even when the underlying image categories are common.
This benchmark reveals a key weakness: models that perform well on familiar data often fail to recognize atypical instances, such as identifying a chair in an unusual setting or spotting a vehicle from an unexpected angle.
HAROOD: Human Activity Recognition OOD Scenarios
HAROOD (Human Activity Recognition Out-of-Distribution) focuses on sensor-based data and examines four distinct OOD scenarios: cross-person, cross-position, cross-dataset, and cross-time. It brings together 6 public datasets and evaluates 16 different algorithms using both CNN and Transformer architectures.
The results challenge the idea that one method can excel across all scenarios. Wang Lu, Yao Zhu, and Jindong Wang reported:
No single method consistently outperforms others, highlighting substantial opportunity for advancement.
The inconsistency across scenarios - whether dealing with different individuals, body positions, datasets, or timeframes - shows that sensor-based OOD challenges require tailored solutions rather than a universal approach. These findings emphasize the complexity of achieving robust OOD generalization in this domain.
Performance Patterns and Challenges in OOD Benchmarks
Testing AI models across various benchmarks reveals critical challenges as systems encounter unfamiliar data. These performance trends expand on earlier discussions, helping researchers understand where models falter and pinpoint areas that require deeper investigation.
Inverse ID-OOD Performance Correlations
An interesting trend in many OOD benchmarks shows that models performing well on familiar data often do better with unseen data too. This phenomenon, called "accuracy on the line," might seem counterintuitive. You’d expect models overfitting to training data to struggle with new scenarios. However, as Olawale Salaudeen and colleagues point out, this accuracy boost often stems from benchmarks that fail to disrupt spurious correlations:
Gains in in-distribution accuracy generally improve OOD accuracy, a phenomenon termed accuracy on the line, which contradicts the expected harm of spurious correlations.
This happens because many "misspecified" benchmarks don’t disrupt the unstable statistical shortcuts models pick up during training. As a result, models keep relying on these patterns, giving the illusion of robustness. Researchers now suggest auditing benchmarks to ensure they genuinely test whether models depend on spurious features. If in-distribution and OOD performance rise in perfect sync, the benchmark likely isn’t pushing the model’s robustness boundaries.
Vision-Language Models: Challenges with Complex Reasoning
Vision-language models face significant challenges with tasks requiring counting, logical reasoning, and multi-step inference under OOD conditions. Yannic Neuhaus, Nicolas Flammarion, Matthias Hein, and Francesco Croce studied multimodal LLMs using grid-based navigation tasks. While Chain-of-Thought (CoT) reasoning improved model performance on familiar map sizes, their performance dropped sharply on larger, unseen maps. As the researchers noted:
Out-of-distribution generalization (e.g., to larger maps) remains very limited in most cases when controlling for trivial matches with the ID data.
This suggests that visual modalities introduce complexities that current architectures struggle to generalize. Instead of learning transferable reasoning strategies, models often memorize specific spatial patterns.
Underexplored Areas: Time Series and Sensor Data
Time series and sensor data present unique challenges due to their non-stationary patterns, which frequently shift in real-world settings. The first comprehensive review of time series OOD methodologies, published in March 2025, highlights how new this area of research is. Lead author Xin Wu emphasized the difficulty:
Time series frequently manifest distribution shifts, diverse latent features, and non-stationary learning dynamics, particularly in open and evolving environments.
Traditional benchmarks like ImageNet-C are becoming less useful for today’s web-scale models. For example, Fanfei Li and colleagues introduced LAION-C, which includes 6 new distortion types designed to remain OOD even for models trained on massive datasets like LAION. Many models trained on web-scraped data have already encountered common corruptions like blur or JPEG artifacts, making older benchmarks less effective. This highlights the need for benchmarks that reflect real-world "natural interventions" - such as shifts caused by events like pandemics - to better evaluate model robustness.
Methods to Improve OOD Generalization
Improving out-of-distribution (OOD) generalization involves refining algorithms and adopting smarter training methods to create systems capable of maintaining performance when faced with unfamiliar data.
Algorithm Improvements for Robustness
Techniques like Invariant Risk Minimization (IRM), stable learning, and domain generalization are key components of OOD robustness strategies. However, a recurring challenge is that algorithms performing well on one type of distribution shift often struggle with others. On the other hand, web-scale pre-training has emerged as a game-changer, with developers increasingly combining multiple strategies rather than relying on a single method. Multimodal Large Language Models (MLLMs) stand out for their ability to handle distortions, with top-performing models now rivaling or even surpassing human observers on certain robustness tasks. This marks a significant shift from earlier years when humans consistently outperformed AI systems in OOD scenarios. These advancements in algorithms pave the way for more effective benchmark-driven training.
Benchmark-Driven Model Training
Using diverse benchmark datasets during training equips models to handle multiple types of distribution shifts at once. Benchmarks serve as a comparative framework for evaluating approaches like domain generalization and IRM within a unified testing environment. The most effective benchmarks focus on natural distribution shifts, such as variations in geography, camera settings, and image styles, rather than relying solely on synthetic corruptions.
Interestingly, data augmentation methods derived from benchmark testing can outperform models trained on datasets with 1,000 times more labeled data. These insights build on earlier benchmark results to address both existing and emerging OOD challenges. However, traditional benchmarks often fall short when applied to massive training datasets. To address this, LAION-C introduces six new distortion types to ensure evaluations remain genuinely OOD.
Testing in Practical Environments
To validate models for real-world use, it’s essential to test them against multiple distribution shifts simultaneously. Dan Hendrycks and his team highlighted this necessity:
Future research must study multiple distribution shifts simultaneously.
Beyond training, testing in practical environments ensures models are reliable under real-world conditions. This involves incorporating benchmarks that account for geographic diversity and camera-specific variations, rather than focusing solely on standard image corruptions. Some augmentation techniques that improve robustness to texture and local image statistics fail to address shifts like geographic changes. Incorporating psychophysical experiments that compare model performance to human robustness establishes a high standard for OOD evaluation. Regularly updating test suites is also crucial to avoid overlap with web-scale training data, ensuring evaluations remain genuinely OOD.
Conclusion
The challenges of out-of-distribution (OOD) generalization remain pressing, as highlighted by benchmarks like OODBench, HAROOD, WOODS, and LAION-C. These benchmarks reveal that even the most advanced models struggle when confronted with unfamiliar data patterns. For example, GPT-4o achieves over 90% accuracy on in-distribution samples but drops to around 65% when tested on more difficult OOD data. This significant gap in performance exposes the limitations of traditional benchmarks, especially as models trained on massive datasets often fail to handle common corruptions effectively.
Researchers have pinpointed patterns critical for future progress. Ling Lin and colleagues from OODBench noted:
Failure to appropriately handle out-of-distribution (OOD) objects may introduce safety risks in real-world applications (e.g., autonomous driving or medical assistance).
No single algorithm consistently excels across all OOD scenarios, whether in tasks like sensor-based human activity recognition or visual planning. This reality suggests that combining multiple strategies is more effective than relying on a single approach.
Advancements like web-scale pre-training and multimodal architectures have reshaped the field. Fanfei Li and colleagues observed:
the best models now matching or outperforming the best human observers
when it comes to robustness against certain image corruptions. However, while reasoning strategies like Chain-of-Thought enhance in-distribution performance, they often fall short on OOD tasks.
To keep pace with evolving models, benchmark-driven development must focus on new distortion types and automated assessment metrics. For instance, OODBench introduced 40,000 instance-level OOD pairs, and LAION-C added six new distortion types. Testing models against diverse real-world shifts - like geographic variations or sensor-specific changes - helps ensure reliability beyond controlled environments. These adaptive metrics directly address the gaps and challenges outlined earlier.
FAQs
Which OOD benchmark should I use for my data type?
The most suitable OOD benchmark varies based on your data type and specific task:
- Vision/Multimodal: OODBench tests large vision-language models with a dataset of 40,000 instances.
- Language: ThinkBench targets reasoning tasks, offering 3,000 samples for evaluation.
- Time Series: WOODS includes 10 benchmarks tailored for temporal data analysis.
- Sensor Data: HAROOD focuses on human activity recognition under OOD scenarios.
- Object Detection: COUNTS delivers detailed annotations to study distribution shifts effectively.
Why can higher in-distribution accuracy still mean weak OOD robustness?
Models achieving high accuracy on in-distribution data don't necessarily perform well on out-of-distribution (OOD) data. This happens because they often depend on spurious correlations - patterns in the training data that don't hold up when the distribution changes. As a result, even with strong in-distribution performance, their ability to generalize can fall apart under different conditions.
What’s the most practical way to improve and test OOD generalization?
Fine-tuning pre-trained models using the right combination of model size and dataset is one of the most effective ways to improve and test out-of-distribution (OOD) generalization. Larger models and datasets often lead to better outcomes. To assess robustness in practical scenarios, use diverse benchmarks such as CNS-Bench and OpenOOD v1.5. These tools help evaluate how well models perform under real-world conditions.
Testing under challenging situations - like noisy, corrupted, or adversarial data - can reveal how reliably a model handles unpredictable environments. Combining thorough evaluation methods with careful model selection is key to achieving dependable performance.