Attention in Stable Diffusion Models
Attention mechanisms are the core of Stable Diffusion models, ensuring text prompts align with generated images. These systems rely on self-attention to maintain image structure and cross-attention to connect text and visual features. Recent advancements, like the joint-attention approach in Stable Diffusion 3, allow text and image data to influence each other while preserving their unique traits.
Key points:
- Self-Attention: Manages spatial relationships within images.
- Cross-Attention: Links text prompts to image features for accurate generation.
- Joint-Attention: Combines text and image embeddings for improved results in Stable Diffusion 3.
- Efficiency: Latent space processing reduces computational load.
- Challenges: High-resolution image generation is resource-intensive, but newer models like SANA address this with linear attention.
Stable Diffusion balances performance, accuracy, and resource needs, making it suitable for both consumer-grade GPUs and advanced applications. Advanced versions improve text rendering and efficiency but often require more powerful hardware.
1. Stable Diffusion
Cross-Attention Mechanisms
Stable Diffusion employs cross-attention to link text prompts with image generation. In this process, latent image features act as Queries (Q), while text embeddings from encoders like CLIP serve as Keys (K) and Values (V). This setup ensures that specific parts of the image focus on relevant text tokens. For instance, if you type "cat", cross-attention ensures that certain regions of the image respond to that word, rather than applying the concept of "cat" uniformly across the entire image.
The U-Net architecture integrates cross-attention layers at various resolutions. Coarser resolutions, like 8×8, handle the overall composition and layout of the image, while finer resolutions, such as 32×32, focus on detailed textures and shapes. Attention maps guide the spatial alignment between text tokens and image regions, helping the model learn how text and image features correspond.
While cross-attention aligns text and image features, self-attention works alongside it to maintain internal consistency within the image.
Self-Attention Mechanisms
Self-attention focuses on spatial relationships within the image itself. While cross-attention connects text to image features, self-attention ensures that different parts of the image interact cohesively, preserving structural details and maintaining shape consistency during generation.
The architecture combines self-attention and cross-attention in an interleaved manner. Self-attention ensures spatial coherence within the image, while cross-attention provides the necessary text-based conditioning.
Computational Efficiency
Stable Diffusion achieves efficiency by operating in latent space rather than pixel space. This approach significantly reduces the computational burden. For example, a 512×512 image is compressed into a 64×64 latent representation, dramatically lowering the data volume. This compression not only enhances performance but also makes self-attention at the U-Net bottleneck approximately 4,096× less resource-intensive compared to models working directly in pixel space.
This efficiency translates into practical benefits. While pixel-space models typically require over 40GB of VRAM, Stable Diffusion 1.5 operates with just around 4.5GB. Additionally, a scaling factor of 0.18215 is applied to VAE latents to normalize their variance before the diffusion process begins.
Multimodal Fusion Approaches
Stable Diffusion 3 introduced joint-attention through the MMDiT architecture, which represents a departure from traditional U-Net designs. By using separate weights for image and language representations, this approach enhances text understanding and improves spelling accuracy. It allows each modality to retain its unique characteristics while still influencing one another during the attention process.
"Our new Multimodal Diffusion Transformer (MMDiT) architecture uses separate sets of weights for image and language representations, which improves text understanding and spelling capabilities".
More recent versions also incorporate multiple text encoders to enrich semantic conditioning. For example, SDXL uses CLIP-L and OpenCLIP-bigG for 2,048-dimensional conditioning, while Stable Diffusion 3 adds T5-XXL. However, removing the 4.7-billion-parameter T5 text encoder reduces memory usage at the expense of typography performance.
sbb-itb-903b5f2
Cross Attention | Method Explanation | Math Explained
2. Other Diffusion Architectures
Expanding on the techniques used in Stable Diffusion, other diffusion architectures are pushing boundaries with fresh methods and designs.
Joint-Attention Mechanisms
Architectures like Flux and AuraFlow take a different approach by introducing joint-attention through hybrid designs. These models use "dual-stage blocks", enabling text and image representations to interact bidirectionally before merging the outputs into a single sequence for subsequent "single blocks". This bidirectional interaction enhances feature alignment beyond what traditional cross-attention can achieve.
For instance, Flux.1-Dev, a model with 12 billion parameters, showcases innovation through parallel layer fusion. By combining matrix multiplications for QKV projections with the first MLP layer into one operation, it boosts hardware efficiency.
Linear Attention Mechanisms
The SANA architecture tackles the computational challenges of standard self-attention, which scales quadratically ($O(L^2)$), by using linear attention with $O(L)$ complexity. This method applies linear self-attention to noisy latents while retaining regular cross-attention for interactions between text and latents. The result? Faster processing for high-resolution image generation without compromising quality.
Computational Efficiency
Efficiency is a key focus for models like Lumina-Next, which employs Grouped-Query Attention (GQA) to cut down memory usage by limiting the space required for keys and values. Additionally, Rotary Position Embeddings (RoPE), now widely used in models like Flux and Lumina, help these systems handle longer sequences and adapt to different image resolutions.
Another trend is the shift from U-Net architectures to Diffusion Transformers (DiT). Models such as SD3, Flux, and PixArt-Alpha emphasize scalability and better compositional handling, moving away from U-Net's multi-scale feature extraction. These models also lean on rectified flow instead of traditional DDPM noise schedules, creating more direct inference paths. This adjustment enables high-quality generation in just 20–30 steps.
These developments highlight the ongoing quest to balance efficiency and quality across diffusion-based models.
Advantages and Disadvantages
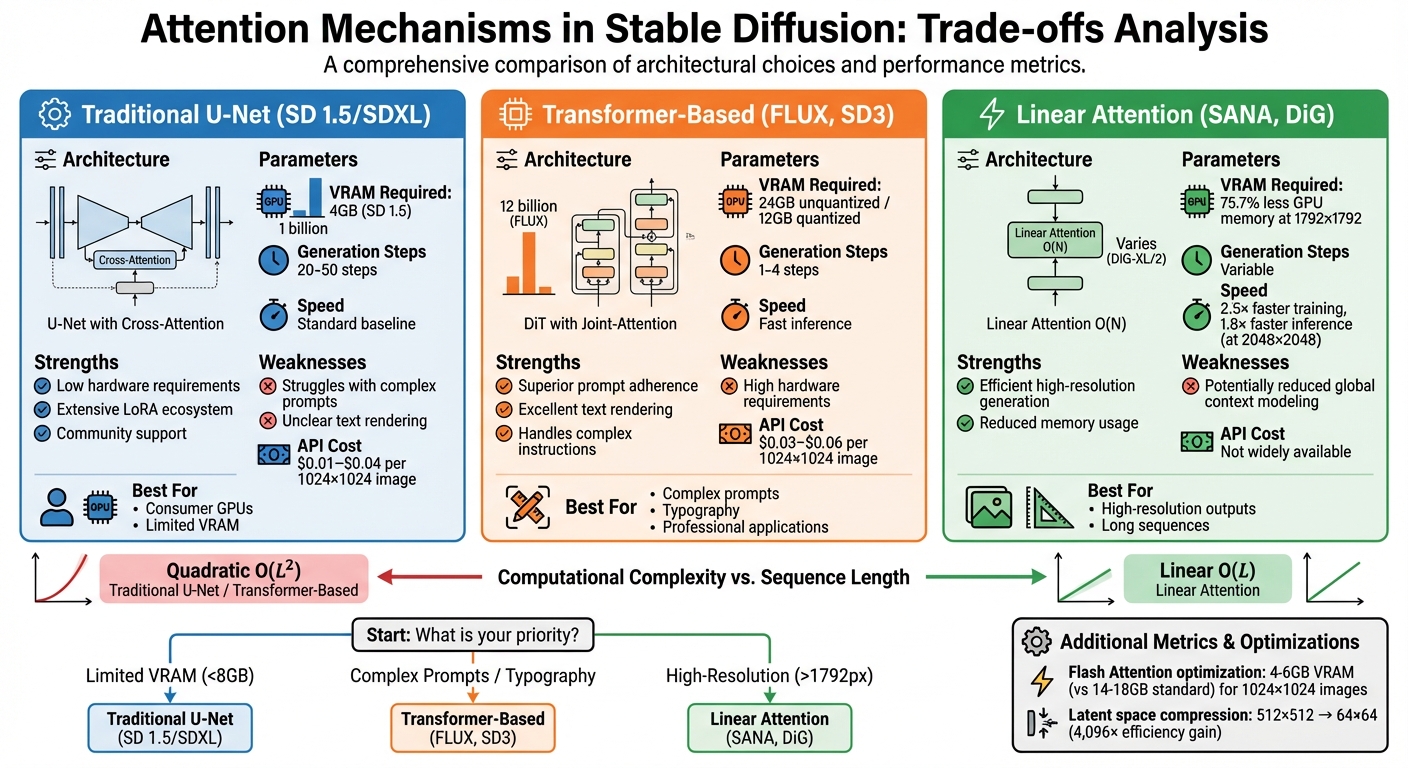
Comparison of Stable Diffusion Attention Mechanisms: Performance vs Resource Requirements
This section looks at the trade-offs involved with different attention mechanisms, focusing on hardware needs, computational efficiency, and cost.
Choosing an attention mechanism often requires balancing quality, speed, and resource use.
Traditional Stable Diffusion models like v1.5 and SDXL, which rely on U-Net architectures with cross-attention, are designed to run efficiently on modest hardware. For example, Stable Diffusion 1.5 can function with just 4GB of VRAM, making it accessible for consumer GPUs. However, these models typically need 20–50 steps to generate high-quality images. They may also have difficulty with complex prompts, sometimes producing unclear text or omitting key details.
Transformer-based models, such as FLUX and SD3, perform better in terms of prompt adherence and text rendering, producing images in as few as 1–4 steps. That said, FLUX Dev requires 24GB of VRAM for unquantized outputs (or 12GB when quantized) and uses a much larger parameter count - 12 billion compared to just 1 billion in SD 1.5.
Linear attention models like DiG strike a middle ground. For instance, DiG-S/2 achieves 2.5× faster training speeds and saves 75.7% of GPU memory at a resolution of 1792×1792 by employing linear (O(N)) scaling instead of quadratic scaling. At 2048×2048 resolution, DiG-XL/2 is 1.8× faster than DiT when using FlashAttention-2. However, this efficiency may come at the cost of reduced global context modeling.
"The integration between diffusion transformer architecture and flow matching leads to significant improvements in image quality. The model can produce images with finer details, sharper textures, and more accurate representations of the input text prompts." - Superteams.ai
Pricing also varies between models. FLUX API costs range from $0.03 to $0.06 per 1024×1024 image, while Stable Diffusion APIs are generally priced between $0.02 and $0.04, with some third-party providers offering rates as low as $0.01. For users running models locally, Stable Diffusion benefits from a well-established ecosystem with thousands of LoRAs and extensive community support, offering flexibility that newer architectures have yet to match.
Conclusion
Examining the progression of attention mechanisms in Stable Diffusion highlights the trade-offs involved in applying these models to practical scenarios. Traditional U-Net architectures rely on a mix of self-attention and cross-attention to understand spatial relationships and incorporate text prompts. However, they can face challenges when handling intricate instructions or typography. The newer Stable Diffusion 3 models address these limitations by introducing joint-attention, which combines text and image data streams while maintaining separate weights for each.
"Since text and image embeddings are conceptually quite different, we use two separate sets of weights for the two modalities... this is equivalent to having two independent transformers for each modality, but joining the sequences of the two modalities for the attention operation." - Stability AI
Linear attention, as implemented in SANA, offers a solution to the quadratic complexity problem, making high-resolution image synthesis more efficient. At the same time, self-attention remains essential for preserving geometric details during image editing. Cross-attention, while useful, can sometimes lead to object attribution issues that result in editing errors.
Choosing the appropriate attention mechanism depends on your specific needs. If you’re working with limited VRAM, traditional Stable Diffusion models are still a practical choice. On the other hand, for tasks that demand precise typography or the ability to follow complex instructions, joint-attention architectures like Stable Diffusion 3 provide better results, though they require more computational resources. For high-resolution outputs or long sequences, linear attention stands out as an efficient option, avoiding the memory challenges associated with quadratic scaling.
Hardware innovations like Flash Attention further enhance accessibility by drastically reducing VRAM requirements. For example, generating 1,024×1,024 images can now be done with just 4–6 GB of VRAM instead of the typical 14–18 GB. These advancements make advanced attention mechanisms more feasible for users with consumer-grade GPUs.
FAQs
When should I choose self-attention vs cross-attention?
Self-attention works best when you need to understand relationships within a single sequence, like the connections between different parts of an image or the tokens in a text prompt. It strengthens the internal dependencies within the same type of data, making it ideal for tasks that focus on one modality.
Cross-attention, however, is designed to bridge two different modalities. For example, it’s used to align text prompts with image features. This makes cross-attention particularly useful for tasks like text-guided image generation or editing, especially in models like Stable Diffusion.
How does joint-attention in Stable Diffusion 3 improve text rendering?
Joint-attention in Stable Diffusion 3 takes text rendering to a new level by sharpening spatial reasoning and pinpointing writing areas with precision. By using token-wise spatial attribution, it ensures clearer multi-line layouts and delivers more accurate dense typography.
What makes linear attention better for high-resolution images?
Linear attention streamlines the process of handling high-resolution images by cutting down computational complexity from quadratic to linear. This means image generation becomes faster without sacrificing quality. It's especially useful for models like Stable Diffusion, where balancing efficiency and performance is key to managing intricate visual details.